使用 AppSwitch 精简 Istio 层次
使用 AppSwitch 自动接入应用并降低延迟。
Sidecar proxy 模式成就了很多奇迹。Sidecar 身处微服务的数据路径之中,能够精确的了解到应用程序的意图。它在应用程序级别而非网络层级别对流量进行监控和协议的检测,从而实现了深度的可见性、访问控制以及流量管理能力。
如果我们仔细观察,在执行应用流量的高级分析之前,数据必须通过许多中间层。这些层中的大部分都是基础设施的一部分,是数据传输的管道。这样一来,就增加了数据通信的延迟,也提高了整个系统的复杂性。
多年以来,在网络数据路径层内实现积极的细粒度优化方面,已经有了很多集体努力。每次迭代可能都节省了几个毫秒。但这些层本身的必要性却无人质疑。
优化层还是删除层
在我看来,在对某些东西进行优化之前,应该先行考虑的是这个方面的需求是否可以取消。我最初的操作系统级虚拟化工作目标(broken link: https://apporbit.com/a-brief-history-of-containers-from-reality-to-hype/),就是移除虚拟机(broken link: https://apporbit.com/a-brief-history-of-containers-from-reality-to-hype/),用 Linux 容器直接在主机操作系统上运行应用,从而免除中间层的困扰。很长一段时间里,业界都在努力的对虚拟机进行优化,这是一场错误的战斗,真正应该做的是删除附加层。
在微服务以及网络的连接方面,历史再次重演。网络已经经历了物理服务器十年前所经历的变化。新引进层和结构正被深入集成到了协议栈甚至是晶片之中,却没有人认真考虑替代的可能。也许移除这些附加层才是更好的办法。
这个问题我已经思考了一段时间,我相信网络栈应该可以借鉴容器的做法,能够从基础上简化应用端点跨越复杂中间层进行连接的过程。我从容器的原始工作中总结的原则,也被应用到了创建 AppSwitch 的过程之中。容器所提供的接口可以直接被应用拿来消费,AppSwitch 会直接插入到应用程序所用的定义良好的网络 API 之中,并跳过所有中间层,直接将应用程序的客户端连接到适当的服务器上。这才是网络的应有之意。
在详细说明 AppSwitch 如何从 Istio 栈中清理无用层次之前,首先介绍一下产品架构。更多内容请移步浏览产品文档页面。
AppSwitch
和容器运行时相比,AppSwitch 由客户端和一个守护进程组成,二者通过 HTTP 协议的 REST API 进行通信。客户端和守护进程构建为一个自包含的二进制文件 ax。客户端透明的注入 s 应用程序,并追踪网络相关的系统调用,随后通知守护进程。例如一个应用进行了 connect(2) 系统调用,目标是一个 Kubernetes 服务的 IP。AppSwitch 客户端拦截这一调用并令其失效,然后把这一事件及其参数和上下文环境告知守护进程。守护进程会处理系统调用,例如代表应用程序直接连接到上游服务器的 Pod IP。
值得注意的一点是,AppSwitch 的客户端和服务器之间不做任何数据转发。它们中间会通过 Unix socket 交换文件描述符,从而避免数据拷贝。另外客户端也不是独立进程,而是运行在应用本身的上下文之中的,因此应用和 AppSwitch 之间也不存在数据拷贝的操作。
删减堆栈层
现在我们大概知道了 AppSwitch 的功能,接下来看看它从标准服务网格中优化掉的层。
网络的去虚拟化
Kubernetes 为运行其上的微服务应用提供了简单的设计优良的网络结构。然而为了支持这些设计,也为下层网络强加了特定的 需求。要符合这些需求并不简单。通常会通过另加一层的方式来满足要求。典型方案就是在下层网络和 Kubernetes 之间加入叠加层。应用产生的流量会在源头进行封包,在目的地进行解包,这一过程消耗的不仅是网络资源,还包括 CPU。
AppSwitch 会通过和平台之间的接触,来决定应用程序的可见范围。它会为应用程序提供一个关于下层网络的虚拟视图,这一视图类似于叠加层,但是不会在数据路径中引入额外的处理工作。和容器的情况类似,容器内部看起来也像是一个虚拟机,但是其基础实现不会干扰低级中断之类的高发事件的控制过程。
AppSwitch 能注入到标准的 Kubernetes 清单文件之中(和 Istio 注入类似),这样应用的网络就直接被 AppSwitch 控制,跳过任何的网络叠加过程。稍后介绍更多细节。
容器网络的组件
将网络从主机扩展到容器是一个 巨大挑战。新的网络层应运而生。容器中的进程只是主机上的一个进程。然而应用所期待的网络抽象和容器网络命名空间之间存在一个 错位,进程无法直接访问主机网络。应用程序眼里的网络是 Socket 或者 Session,而网络命名空间暴露的是设备抽象。一旦进入网络命名空间,进程会失去所有连接。为此发明了 veth-pair 之类的工具用来弥合这一鸿沟。数据现在必须从主机接口进入虚拟交换机,然后通过 veth-pair 才能进入容器网络空间里面的虚拟网络接口。
AppSwitch 能够有效的移除连接两端的虚拟交换机和 veth-pair 层。运行在主机上的守护进程所用的主机网络既然已经就绪,就无需再使用网桥方式把主机网络桥接到容器了。主机上创建的 Socket 文件描述符被传递给运行在 Pod 网络命名空间中的应用程序。应用收到 FD 之后,控制路径的所有工作都已就绪,就可以使用 FD 进行实际 IO 了。
跳过共生端点的 TCP/IP
TCP/IP 几乎是所有通信过程的媒介。如果恰好应用端点处于同一主机,还有必要继续使用 TCP/IP 么?毕竟 TCP/IP 会完成很多工作,并且非常复杂。Unix Socket 是为主机内通信设计的,AppSwitch 可以透明的将共生端点之间的通信切换到 Unix Socket 上。
应用所监听的每个 Socket,AppSwitch 都会管理两个监听 Socket,一个对应 TCP,一个对应 Unix。当客户端尝试连接到的服务器恰好在同一主机,AppSwitch 守护进程就会选择连接到服务器的 Unix 监听 Socket 上。连接两端的 Unix Socket 被传递给相应的应用程序之中。返回完成的连接 FD 之后,应用会把它当做简单的字节管道。协议真的不重要。有个应用偶尔会做一些协议相关的调用,例如 getsockname(2),AppSwitch 会自行处理。它会提供一致的响应,保证程序持续运行。
数据推送代理
我们一直在讨论移除层的问题,再回头看看代理层自身的需求。有时候代理服务器可能退化成为普通的数据推送装置:
- 可能不需要协议解码。
- 协议可能不被代理支持。
- 通信过程是加密的,代理无法访问其中的 Header。
- 应用(Redis、Memcached 等)对延迟非常敏感,无法忍受中间代理服务器的花销。
这些情况下,代理服务器和低层的管道层并无区别。实际上,代理无法对这种情况作出合适的优化,这种延迟可能会更高。
举例说明,看看下图的应用。其中包含了一个 Python 应用以及一组 Memcached。根据连接时间进行路由,选择了一个 Memcached 作为上游服务器。速度是这里的首要考量。
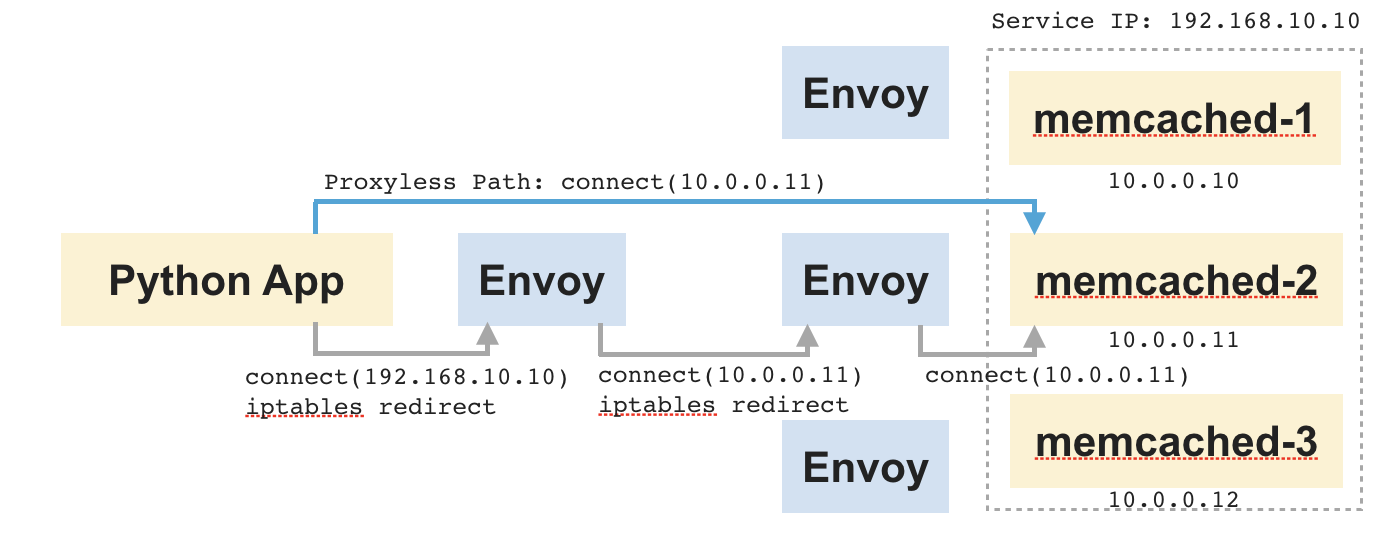
浏览图中的数据流,Python 应用发起了到 Memcached IP 的连接。该连接被重定向到客户端的 Sidecar。Sidecar 把连接路由到一个 Memcached 服务器,并在两个 Socket 之间复制数据——一端是应用,一端是 Memcached。同样的事情也发生在服务端的 Sidecar 和 Memcached 之间。这一场景之下,代理服务器的角色只是无聊的在两个 Socket 之间传送字节流,同时还给端到端连接造成了大量延迟。
想象一下,如果应用跳过两个代理,直接连接到 Memcached。数据会在应用和 Memcached 服务之间直接流动。AppSwitch 在 Python 应用发起 connect(2) 系统调用时会透明地对系统调用的目标地址进行调整。
无代理的协议解码
这一节要谈的事情有点奇怪。在前面我们看到,在无需了解流量内容的情况下,可以跳过代理服务器。但是其它场景呢?也是可以的。
在典型的微服务通信场景中,Header 中会有很多有用的信息。Header 之后会是信息本体或者负载,这些构成通信的主体。这里代理服务器再一次退行成为数据推送器。AppSwitch 为这些用例提供了一个花招,用于跳过代理服务器。
虽说 AppSwitch 并非代理,它会对应用端点之间的连接进行仲裁,还能访问对应 Socket 的文件描述符。通常 AppSwitch 简单的把这些 FD 传给应用。但是它也可以使用 recvfrom(2) 系统调用的 MSG_PEEK 选项查看连接上收到的初始消息。这样 AppSwitch 就能在不从 Socket 缓冲区中取出信息的情况下获取流量的内容。当 AppSwitch 将 FD 发给应用并退出数据路径之后,应用程序才会对连接进行真正的读取。AppSwitch 使用这一技术,对应用级的流量进行深层分析,在不进入数据路径的前提下,实现下面将要谈到的复杂网络功能。
零损耗的负载均衡器、防火墙和网络分析器
负载均衡器和防火墙这样的典型网络功能,通常的实现方式都是引入一个中间层,介入到数据/包之中。Kubernetes 的负载均衡器(kube-proxy)实现利用 iptables 完成对数据包流的探测,Istio 也在代理层中实现了同样的功能。但是如果目标只是根据策略来对连接进行重定向或者丢弃,那么在整个连接过程中都介入到数据通路上是不必要的。AppSwitch 能够更有效的处理这些任务,只要简单的在 API 层面处理控制路径即可。AppSwitch 和应用紧密结合,因此还能够获取更多的应用信息,例如堆栈动态和堆利用情况、服务就绪时间以及活动连接属性等,这些信息可以为监控和分析提供更大发的操作空间。
更进一步,AppSwitch 还能够利用从 Socket 缓冲区获取的协议数据,完成七层负载均衡和防火墙功能。它能够利用从 Pilot 获取的策略信息,合成协议数据和各种其它信号,从而实现高效的路由和访问控制能力。实际上,无需对应用程序自身或配置做出任何变动,AppSwitch 也可以“诱导”应用连接到正确的后端服务器。看起来好像应用程序本身就具备了策略和流量管理能力。
实际上还存在一种可能的黑魔法就是,无需进入数据路径,也能够对应用的数据流进行修改,后面我会专门撰文描述这一功能。目前如果有对应用协议流量进行修改的需要,AppSwitch 当前的实现是使用一个代理,AppSwitch 使用一种高度优化的机制来完成代理任务,下一节将继续说明。
流量重定向
Sidecar 代理要获知应用的协议流量,首先需要接入连接。利用包过滤层改写包,让数据包进入对应的 Sidecar,从而完成对应用程序进入和发出连接的重定向任务。要实现重定向规则,就意味着要编写大量规则,这是很繁琐的工作。Sidecar 捕获的目标子网发生变化时,规则的应用和更新也是很昂贵的操作。
虽说 Linux 社区正在解决一些性能问题,但是还有特权相关的问题:不论何时策略发生变化,iptables 的规则都要随之更新。当前架构下,所有特权操作都是在初始化容器中执行,初始化容器只会在应用启动时执行一次,然后这一特权就会被删除;更新 iptables 规则需要 root 权限,所以如果不重新启动应用,则无法再次执行更新。
AppSwitch 提供了无需 root 特权就能重定向应用连接的方法。这样一个无特权应用也能够连接任何主机。应用程序的所有者无需额外权限,就可以修改应用的 connect(2) 调用时的主机地址。
Socket 委托
接下来看看 AppSwitch 如何在不使用 iptables 的情况下进行连接重定向。想象一下,应用程序能够以某种方式主动传递它用于与 Sidecar 通信的 Socket 文件描述符的话,就不需要 iptables 了。AppSwitch 提供了一种称为 Socket 委托的机制用于完成这一任务。这个功能让 Sidecar 在不更改应用程序的情况下,透明的访问应用程序用于通信的 Socket 文件描述符的副本。
举个例子,在我们的 Python 示例应用中用于完成这一目标的几个步骤。
- 应用初始化一个到 memcached 服务 IP 的连接请求。
- 客户端发出的连接请求被转发给守护进程。
- 守护进程创建一对预连接的 Unix socket(用
socketpair(2)系统调用)。 - 发送 Socket 对中的一端给应用,应用会用这个 FD 进行读写。它还要确保应用始终视其为合法 Socket,以便于侵入所有对连接属性的查询。
- 另外一端会通过一个不同的用于开放守护进程 API 的 Unix Socket 发送给 Sidecar。原始目的之类的信息也会由相同的接口进行传输。
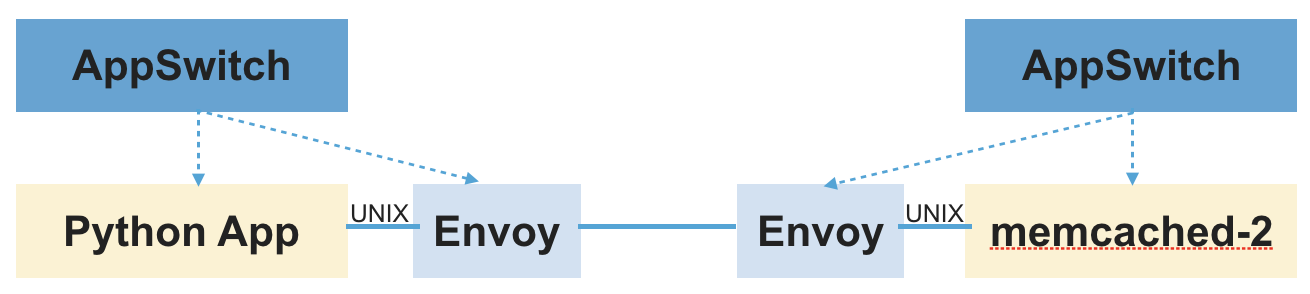
应用和 Sidecar 连接之后,接下来的事情就很普通了。Sidecar 初始化一个到上游服务器的连接,并在从守护进程接收到的 Socket 和连接到上游服务器的 Socket 之间充当数据代理。这里的主要区别在于,Sidecar 得到的连接不是通过 accept(2) 系统调用而来的,而是由守护进程的 Unix socket 来的。Sidecar 不再通过监听来自应用的 accept(2) 通道,而是连接到 AppSwitch 守护进程的 REST 端点获取到的 Socket。
为了完整叙述,再说说服务端发生的事情:
- 应用接收到一个连接。
- AppSwitch 守护进程代应用程序接受这个连接。
- 用
socketpair(2)系统调用创建一对预连接的 Unix Socket。 - Socket 对的一端通过
accept(2)系统调用返回给应用。 - Socket 对的另外一端会和守护进程以应用程序身份接收的 Socket 一起发送给 Sidecar。
- Sidecar 会解开这两个 Socket FD - 一个 Unix Socket FD 连接到应用,另一个 TCP Socket FD 连接到远程客户端。
- Sidecar 会读取守护进程提供的关于远程客户端的元数据,并执行正常操作。
Sidecar 感知的应用
Socket 委托功能对于知晓 Sidecar 存在并希望利用其能力的应用非常有用。应用程序可以通过相同的功能,把 Socket 传递给 Sidecar,委托其进行网络交互。一定程度上,AppSwitch 透明的把每个应用都转换成为了 Sidecar 感知应用。
如何整合这些功能?
退一步看,Istio 把应用程序的连接问题转嫁给 Sidecar,由 Sidecar 代表应用执行这些功能。AppSwitch 对这些服务网格进行了简化和优化,绕过了中间层,仅在确实需要时才调用代理。
接下来讲讲 AppSwitch 可以如何初步集成到 Istio 之中。这不是设计文档,其中涉及到的可能的集成方式并没有经过完全的验证,一些细节还没能解决。这里的尝试是一个大致的将两个系统组合在一起的概要。在这一方案中 AppSwitch 作为一个类似垫片的东西出现在 Istio(应该是网格内应用——译者注)和真正的代理之间。它会作为一个快速通路,用绕过 Sidecar 代理的方式更高效的运作。对于需要使用代理的场合,也会通过移除层的方式缩短数据路径。这篇博客中记录了更多这方面的细节。
AppSwitch 的客户端注入
和 Istio 的 sidecar-injector 类似,AppSwitch 提供了一个 ax-injector 工具用来把 AppSwitch 客户端注入到标准的 Kubernetes 清单文件中。被注入的客户端会透明的监测应用,并把应用程序生成的控制路径上的网络 API 事件报告给 AppSwitch 守护进程。
如果使用了 AppSwitch CNI 插件,还可能仅使用标准 Kubernetes 清单文件,无需注入。这种情况下,CNI 插件会在获得初始化回调时完成必要的注入任务。注入器有以下优点:
- 可以在 GKE 这样的的严格受控的环境中工作。
- 可以轻松的扩展到其它平台,例如 Mesos。
- 同一个集群中可以同时运行标准应用以及启用 AppSwitch 支持的应用。
AppSwitch DaemonSet
AppSwitch 守护进程可以配置成 DaemonSet 的运行方式,也可以作为直接注入应用程序清单的扩展。两种方式下都能够处理来自受支持应用的网络事件。
用于获取策略的 Agent
这一组件用来将 Istio 的配置和策略转达给 AppSwitch。它实现了 xDS API,用来监听 Pilot,并调用对应的 AppSwitch API,来完成守护进程的程控。例如可以把 istioctl 制定的负载均衡策略翻译成等效的 AppSwitch 能力。
AppSwitch 服务注册表的平台适配器
AppSwitch 是存在于应用网络 API 的控制路径上的,因此也就具备了访问集群上服务拓扑的能力。AppSwitch 用服务注册表的形式公布信息,这个注册表会随着应用和服务的变化来自动的进行同步更新。Kubernetes 之外的平台适配器,例如 Eureka,会为 Istio 提供上游服务的详细信息。这虽然并非必要,但更有助于上面提到的 AppSwitch Agent 关联从 Pilot 接收到的端点信息。
代理集成和链路
通过前面讨论过的 Socket 委托机制,能够将需要深度扫描和应用程序流量突变的连接传递给外部代理。这一过程使用了一个扩展的代理服务器协议。在简单的代理协议参数之外,加入了其它的元数据(包括从 Socket 缓冲区中获取的协议 Header)以及活跃的 Socket FD(代表应用的连接),转发给代理服务器。
代理服务器取得元数据之后会进行处理决策。可能接受连接执行代理任务,也可能重定向给 AppSwitch 从而把连接送入快速通道,当然,还有可能直接丢弃连接。
这个机制中有一点比较有趣,当代理从 AppSwitch 接收一个 Socket 的时候,它可以把这个委托转交给其它代理。实际上 AppSwitch 目前就是这么做的。它会用一个简单的内置代理来检查元数据,然后决定在内部处理连接,还是交出去给外部代理(Envoy)。这种机制可以扩展为插件链条,每个环节都 在其中查找特定签名,链条最后一节完成真正的代理工作。
不仅仅是性能
从数据路径上移除中间层,不仅仅意味着性能的提高。性能提高是好事,但这仅仅是一个副产品。在 API 级别上,有更多的重要提升。
应用接入和策略生成的自动化
在微服务和服务网格之前,流量管理由负载均衡器完成,而访问控制则由防火墙完成。通过 IP 地址和 相对静态的 DNS 名称来鉴别应用。实际上这仍然是当前大多数环境的现状。这样的环境将从服务网格中受益匪浅。相对于新功能的开发来说,转型难度并不高,但是需要对整个基础设施进行重新思考和重新实现,这就需要投入了。目前多数策略和配置存在于负载均衡和防火墙中,现存的上下文需要有一个可扩展的路径来完成到服务网格模型的过渡。
AppSwitch 能够大大简化接入流程。它可以把应用程序源环境投射到目标环境。如果传统应用的配置文件包含了硬编码的 IP 地址或者 DNS 名称,通常是难于迁移的。AppSwitch 可以协助捕获这些应用及其配置,在无需更改的情况下将其接入服务网格。
更大范围的应用和协议支持
众所周知,HTTP 是的现代应用程序领域的主导协议,但是一旦涉及传统应用和环境,我们会遇到各种协议和传输方式。有时候连 UDP 的支持都是必要选项,例如 IBM 的 WebSphere 就广泛的依赖 UDP,多数多媒体应用也在使用 UDP 媒体流。当然,DNS 可能是最多使用的 UDP 应用。AppSwitch 在 API 级别为 UDP 提供了和 TCP 非常相似的支持,它检测到 UDP 连接之后,会透明的在快速路径中进行处理,而不是委托给代理。
保留客户端 IP 以及端到端原则
和保留源网络环境的机制类似,同样也可以保留服务器视角的客户端 IP 地址。在 Sidecar 的干扰下,连接通常是来自于 Sidecar 而非客户端,这样服务端应用看到的对端地址就被替换为代理服务器的 IP。AppSwitch 能让服务器看到客户端的真实地址,进行正确的记录,并且能够通过该地址进行准确的决策。另外 AppSwitch 保留了端到端原则,中间层的存在会打破这一规则,并对真正的底层上下文造成混淆。
访问加密 Header 以增强应用信号
加密流量会阻止服务网格对流量的分析。API 级别的介入提供了一种可行的解决方法。AppSwitch 目前的实现能够在系统调用层面获得对应用网络 API 的访问。然而还有进一步的可能,在应用尚未加密或者已经加密的高级 API 边界上对应用程序施加影响。最终的视角上,应用生成明文数据,在发出之前的某个时间点进行加密。既然 AppSwitch 运行在应用的内存上下文中,因此就可能在更高层的数据中获取到明文。当然要完成这种功能,应用需要进行明确定义并且适合介入。同时这一功能还要访问应用二进制文件的符号表。目前 AppSwitch 还没有实现这一功能。
所以收益如何?
AppSwitch 从标准服务网格中移除了一组层次和操作。到底会对性能造成什么影响?
我们做了一些初级的实验,来对前面提到的 AppSwitch 集成方式在提高性能方面的优化进行定性。这个实验运行在 GKE 上,对应的软件系统包括 Fortio 0.11.0、Istio 0.8.0 以及 AppSwitch 0.4.0-2。在无代理测试中,AppSwitch 守护进程以 DaemonSet 的形式运行在 Kubernetes 集群中,并给 Fortio Pod 注入了 AppSwitch 客户端。这是仅有的两个步骤。这个测试的目的是衡量 100 并发连接的情况下,GRPC 的延迟情况。

初步显示,p50 延迟在有无 AppSwitch 的情况下有高达 18 倍的差距(3.99 毫秒 vs 72.96 毫秒)。如果禁用了日志和 Mixer,差距会缩减为 8 倍。很明显,这一差距就是因为数据路径上的多余层造成的。客户端和服务器分属两台不同主机,因此 Unix Socket 优化在这一场景上没有触发,有理由相信,如果客户端和服务器恰好在同一节点上,延迟会进一步缩小。究其根本,在 Kubernetes 上各自 Pod 中运行的服务器和客户端是通过 GKE 网络上的 TCP Socket 直接连接的——没有隧道、网桥或者代理。
Net Net
从 David Wheeler 的引言开始说到,另起一层并非解决层次过多问题的方案。我的博客中经常提到,目前的网络栈已经层次太多,应该精简,但是 AppSwitch 是不是又加了一层?
是的,AppSwitch 的确是另外一层。然而它的存在,能够移除更多层。这样一来,就把新的服务网格层和传统的网络层无缝的结合在一起。AppSwitch 不但抵消了 Sidecar 的成本,并且随着 Istio 1.0 的到来,还提供了一个从现有应用及其网络环境过度到服务网格世界的桥梁。
可能 Wheeler 的引言可以换个说法:
感谢
感谢 Mandar Jog(Google)进行了多次沟通,讨论 AppSwitch 对 Istio 的存在价值。同时也要感谢对本文稿件进行 Review 的几位朋友(以字母排序):
- Frank Budinsky (IBM)
- Lin Sun (IBM)
- Shriram Rajagopalan (VMware)
Share this blog on social!


