Merbridge: acelera tu mesh con eBPF
Reemplazar reglas de iptables por eBPF permite transportar datos directamente de sockets de entrada a sockets de salida, acortando el datapath entre sidecars y servicios.
El secreto de las capacidades de Istio en gestión de tráfico, seguridad, observabilidad y políticas está en el proxy Envoy. Istio usa Envoy como “sidecar” para interceptar el tráfico de servicios, con la funcionalidad de filtrado de paquetes netfilter del kernel configurada mediante iptables.
Existen limitaciones al usar iptables para realizar esta interceptación. Dado que netfilter es una herramienta muy versátil para filtrar paquetes, se aplican varias reglas de enrutamiento y procesos de filtrado de datos antes de llegar al socket de destino. Por ejemplo, desde la capa de red hasta la capa de transporte, netfilter se usará varias veces con reglas predefinidas, como pre_routing, post_routing, etc. Cuando el paquete se convierte en un paquete TCP o UDP y se reenvía a espacio de usuario, se realizan pasos adicionales como validación del paquete, procesamiento de políticas de protocolo y búsqueda del socket de destino. Cuando un sidecar está configurado para interceptar tráfico, la ruta de datos original puede volverse muy larga, ya que se repiten pasos duplicados varias veces.
Durante los últimos dos años, eBPF se ha convertido en una tecnología en tendencia, y muchos proyectos basados en eBPF se han publicado para la comunidad. Herramientas como Cilium y Pixie muestran grandes casos de uso de eBPF en observabilidad y procesamiento de paquetes de red. Con las capacidades sockops y redir de eBPF, los paquetes pueden procesarse eficientemente transportándose directamente desde un socket de entrada a un socket de salida. En una mesh de Istio, es posible usar eBPF para reemplazar reglas de iptables y acelerar el data plane acortando la ruta de datos.
Hemos creado un proyecto open source llamado Merbridge y, aplicando el siguiente comando a tu clúster gestionado por Istio, puedes usar eBPF para lograr esta aceleración de red.
$ kubectl apply -f https://raw.githubusercontent.com/merbridge/merbridge/main/deploy/all-in-one.yamlCon Merbridge, el datapath de paquetes puede acortarse directamente de un socket a otro socket de destino. A continuación explicamos cómo funciona.
Uso de eBPF sockops para optimizar rendimiento
Una conexión de red es, esencialmente, comunicación mediante sockets. eBPF proporciona la función bpf_msg_redirect_hash para reenviar directamente los paquetes enviados por la aplicación en el socket de entrada hacia el socket de salida. Al entrar en la función mencionada, los desarrolladores pueden ejecutar cualquier lógica para decidir el destino del paquete. Gracias a esta característica, el datapath de paquetes puede optimizarse notablemente en el kernel.
El sock_map es la pieza clave para registrar información para el reenvío de paquetes. Cuando llega un paquete, se selecciona un socket existente del sock_map para reenviar el paquete. Como resultado, necesitamos guardar toda la información de sockets para que el proceso de transporte funcione correctamente. Cuando hay nuevas operaciones de socket — como la creación de un nuevo socket — se ejecuta la función sock_ops. Se obtiene el metadata del socket y se guarda en el sock_map para usarse al procesar paquetes. Un tipo de clave común en el sock_map es un “cuádruple” de direcciones y puertos de origen y destino. Con la clave y las reglas almacenadas en el mapa, se encontrará el socket de destino cuando llegue un nuevo paquete.
El enfoque de Merbridge
Vamos a introducir los principios detallados de diseño e implementación de Merbridge paso a paso, con un escenario real.
Interceptación de tráfico del sidecar de Istio basada en iptables
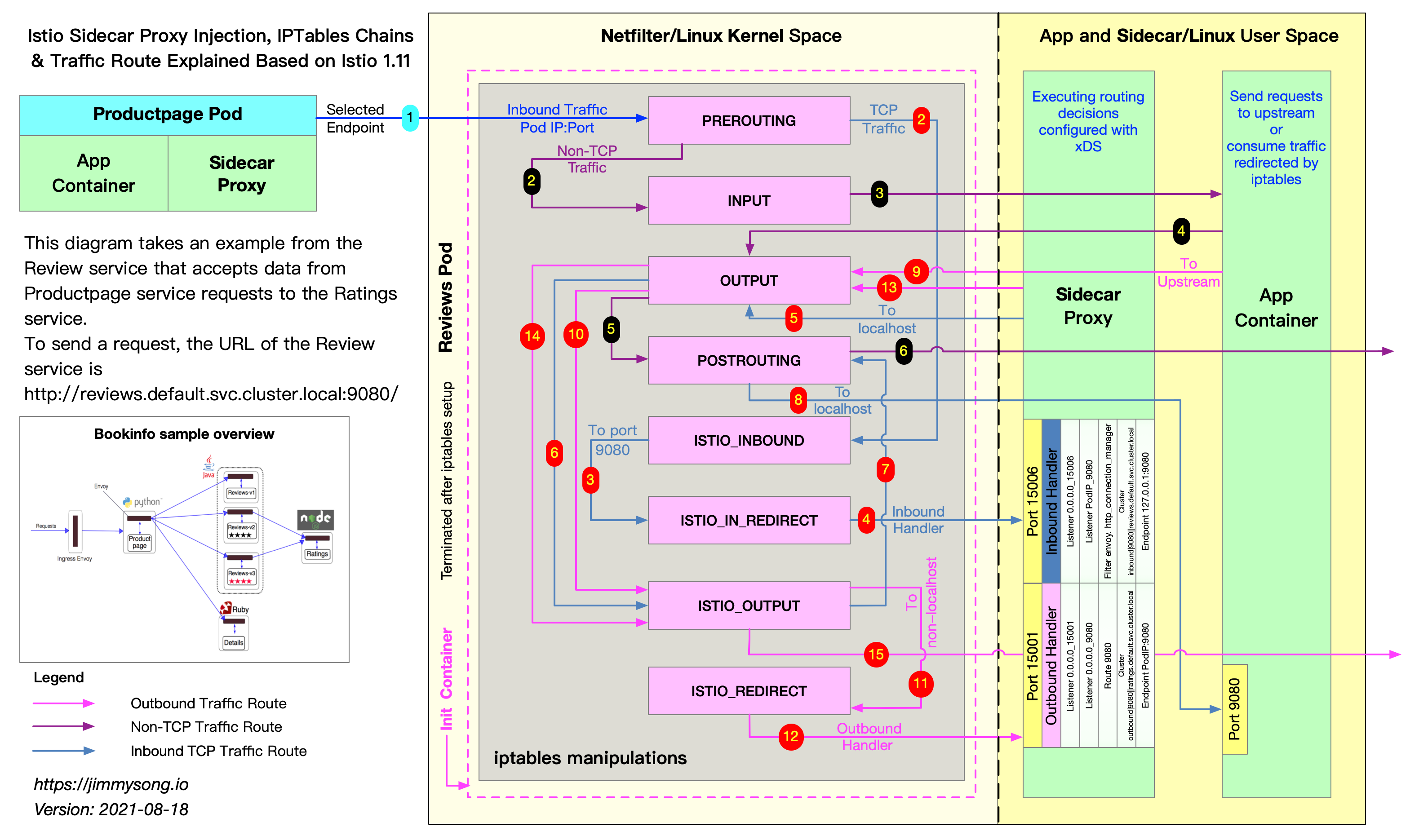
Cuando el tráfico externo llega a los puertos de tu aplicación, será interceptado por una regla PREROUTING en iptables, reenviado al puerto 15006 del contenedor sidecar y entregado a Envoy para su procesamiento. Esto se muestra como los pasos 1-4 en la ruta roja del diagrama anterior.
Envoy procesa el tráfico usando las políticas emitidas por el control plane de Istio. Si se permite, el tráfico se enviará al puerto real del contenedor de la aplicación.
Cuando la aplicación intenta acceder a otros servicios, será interceptada por una regla OUTPUT en iptables y luego se reenviará al puerto 15001 del contenedor sidecar, donde Envoy está escuchando. Esto corresponde a los pasos 9-12 en la ruta roja, de forma similar al procesamiento de tráfico entrante.
El tráfico hacia el puerto de la aplicación debe reenviarse al sidecar y luego enviarse al puerto del contenedor desde el puerto del sidecar, lo cual añade overhead. Además, la versatilidad de iptables determina que su rendimiento no siempre sea ideal, porque inevitablemente añade latencias a todo el datapath al aplicarse distintas reglas de filtrado. Aunque iptables es la forma común de hacer filtrado de paquetes, en el caso del proxy Envoy el datapath más largo amplifica el cuello de botella del proceso de filtrado de paquetes en el kernel.
Si usamos sockops para conectar directamente el socket del sidecar con el socket de la aplicación, el tráfico no tendrá que atravesar reglas de iptables y, por tanto, el rendimiento puede mejorar.
Procesamiento del tráfico de salida
Como se mencionó anteriormente, queremos usar sockops de eBPF para evitar iptables y acelerar las peticiones de red. Al mismo tiempo, no queremos modificar ninguna parte de Istio, para que Merbridge sea totalmente adaptable a la versión de la comunidad. Como resultado, necesitamos simular en eBPF lo que hace iptables.
La redirección de tráfico en iptables utiliza su función DNAT. Al intentar simular las capacidades de iptables usando eBPF, hay dos cosas principales que necesitamos hacer:
- Modificar la dirección de destino cuando se inicia la conexión, para que el tráfico se envíe a la nueva interfaz.
- Permitir que Envoy identifique la dirección de destino original, para poder identificar el tráfico.
Para la primera parte, podemos usar el programa connect de eBPF, modificando user_ip y user_port.
Para la segunda parte, necesitamos entender el concepto ORIGINAL_DST, que pertenece al módulo netfilter en el kernel.
Cuando una aplicación (incluido Envoy) recibe una conexión, llamará a la función get_sockopt para obtener ORIGINAL_DST. Si se pasa por el proceso DNAT de iptables, iptables establecerá este parámetro con el valor “IP + puerto original” en el socket actual. Así, la aplicación puede obtener la dirección de destino original de acuerdo con la conexión.
Tenemos que modificar este proceso de llamada mediante la función get_sockopts de eBPF. (No se usa bpf_setsockopt aquí porque este parámetro no soporta actualmente el optname SO_ORIGINAL_DST).
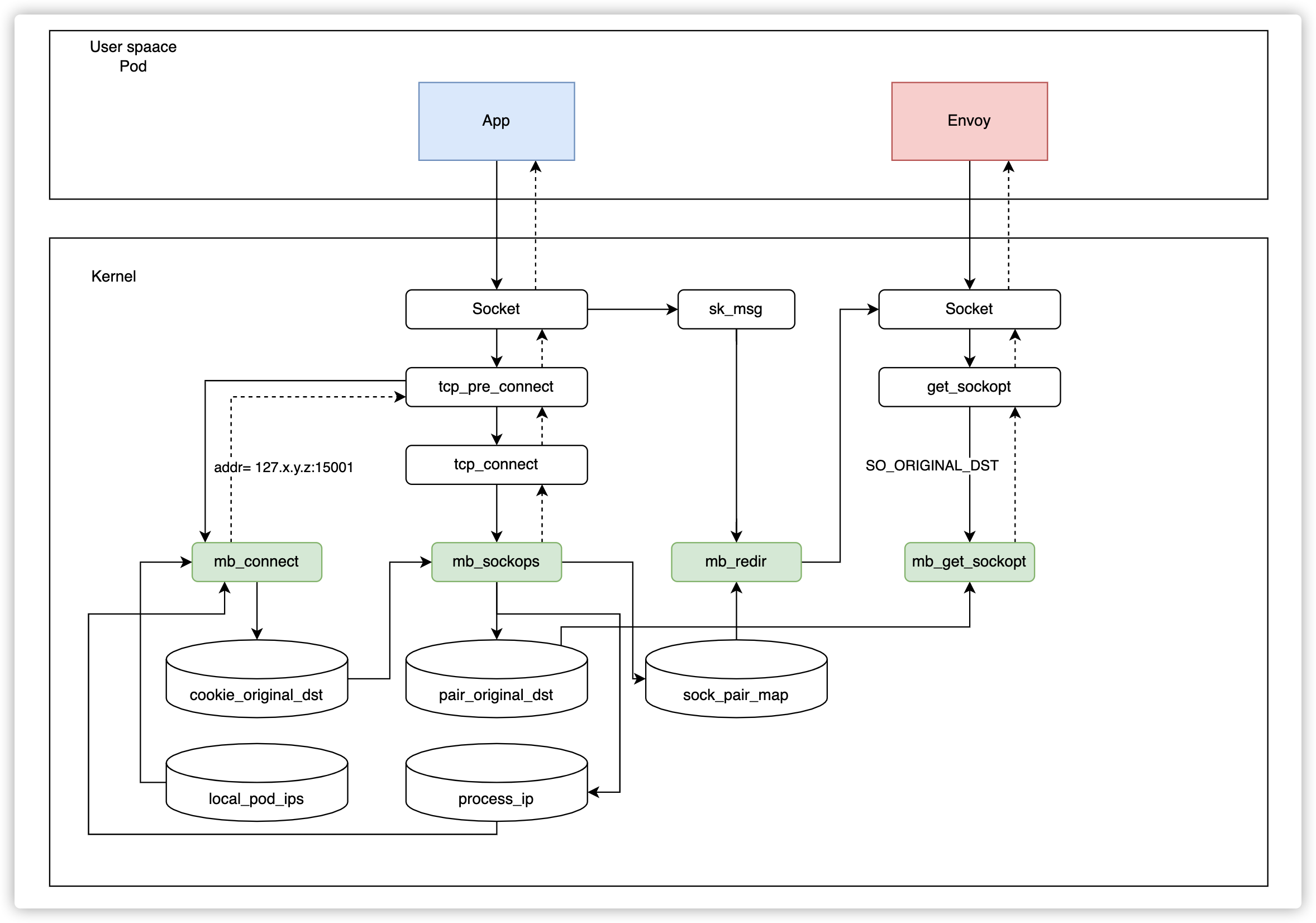
Haciendo referencia a la figura siguiente, cuando una aplicación inicia una petición, seguirá estos pasos:
- Cuando la aplicación inicia una conexión, el programa
connectmodificará la dirección de destino a127.x.y.z:15001y usarácookie_original_dstpara guardar la dirección de destino original. - En el programa
sockops, la información del socket actual y el cuádruple se guardan ensock_pair_map. Al mismo tiempo, el mismo cuádruple y su dirección de destino original correspondiente se escribirán enpair_original_dest. (Aquí no se usa cookie porque no puede obtenerse en el programaget_sockopt). - Después de que Envoy reciba la conexión, llamará a
get_sockoptpara leer la dirección de destino de la conexión actual.get_sockoptextraerá y devolverá la dirección de destino original desdepair_original_dstsegún la información del cuádruple. Así, la conexión queda completamente establecida. - En el paso de transporte de datos, el programa
redirleerá la información del socket desdesock_pair_mapsegún el cuádruple y lo reenviará directamente mediantebpf_msg_redirect_hashpara acelerar la petición.
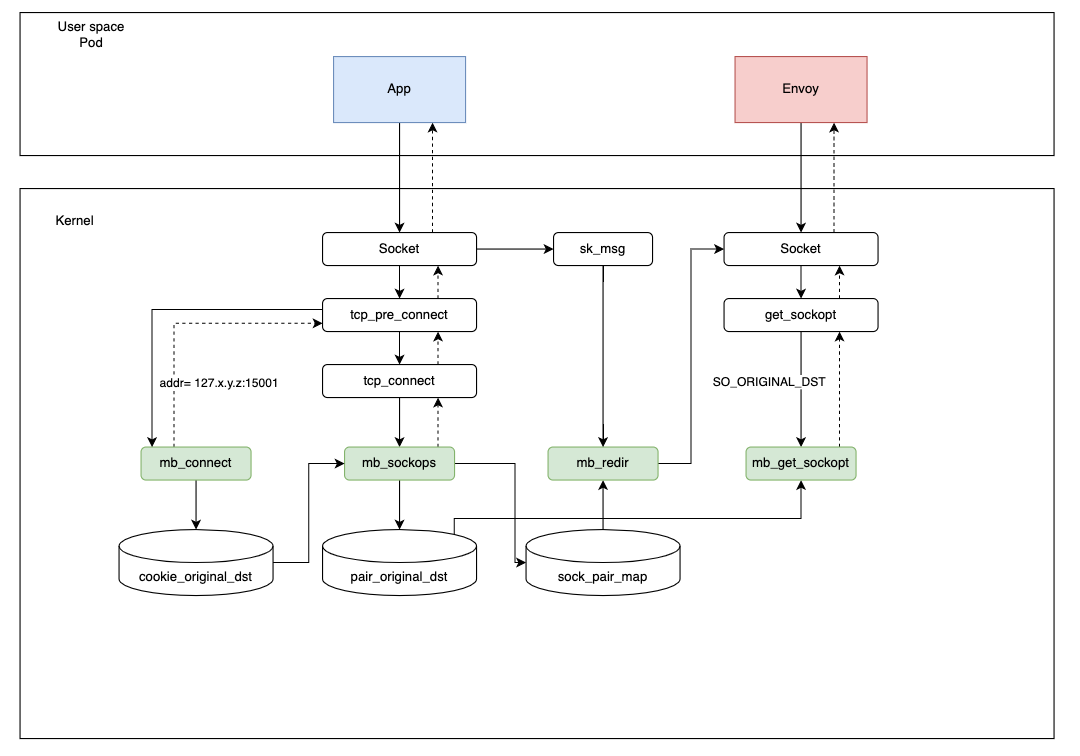
¿Por qué establecemos la dirección de destino como 127.x.y.z en lugar de 127.0.0.1? Cuando existen pods distintos, puede haber cuádruples en conflicto, y esto evita el conflicto de forma elegante. (Las IPs de los pods son diferentes y no estarán en condición de conflicto al mismo tiempo).
Procesamiento del tráfico entrante
El procesamiento del tráfico entrante es básicamente similar al del tráfico de salida, con una única diferencia: se revisa el puerto de destino a 15006.
Cabe señalar que, como eBPF no puede aplicarse dentro de un namespace específico como iptables, el cambio será global; esto significa que si usamos un Pod que originalmente no está gestionado por Istio, o una dirección IP externa, pueden encontrarse problemas serios — como que la conexión no se establezca en absoluto.
Como resultado, diseñamos un pequeño control plane (desplegado como DaemonSet) que observa todos los pods — similar a cómo el kubelet observa pods en el nodo — para escribir en el mapa local_pod_ips las direcciones IP de los pods a los que se les ha inyectado el sidecar.
Al procesar tráfico entrante, si la dirección de destino no está en el mapa, no haremos nada al tráfico.
En caso contrario, los pasos son los mismos que para el tráfico de salida.
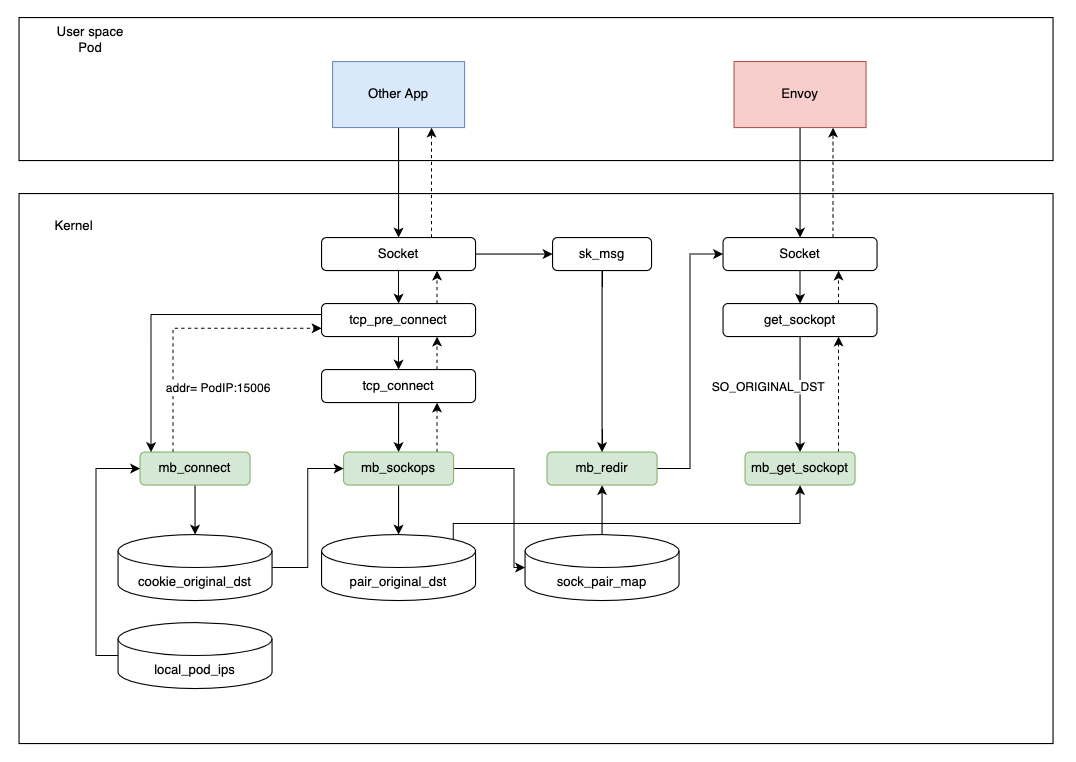
Aceleración en el mismo nodo
Teóricamente, la aceleración entre sidecars Envoy en el mismo nodo puede lograrse directamente mediante el procesamiento de tráfico entrante. Sin embargo, en este escenario Envoy generará un error al acceder a la aplicación del pod actual.
En Istio, Envoy accede a la aplicación usando la IP y el puerto del pod actual. Con el escenario anterior, nos dimos cuenta de que la IP del pod también existe en el mapa local_pod_ips, y el tráfico se redirigirá a la IP del pod en el puerto 15006 de nuevo porque es la misma dirección de la que proviene el tráfico entrante. Redirigir a la misma dirección entrante causa un bucle infinito.
Surge entonces la pregunta: ¿hay alguna forma de obtener la dirección IP en el namespace actual con eBPF? ¡La respuesta es sí!
Diseñamos un mecanismo de feedback: cuando Envoy intenta establecer la conexión, lo redirigimos al puerto 15006. Sin embargo, en el paso sockops determinaremos si la IP origen y la IP destino son iguales. Si lo son, significa que se envió una petición incorrecta y descartaremos esta conexión en el proceso sockops. Mientras tanto, la información actual de ProcessID e IP se escribirá en el mapa process_ip, para permitir que eBPF soporte la correspondencia entre procesos e IPs.
Cuando se envíe la siguiente petición, no será necesario repetir el mismo proceso. Comprobaremos directamente en el mapa process_ip si la dirección de destino es la misma que la dirección IP actual.
Relación de conexiones
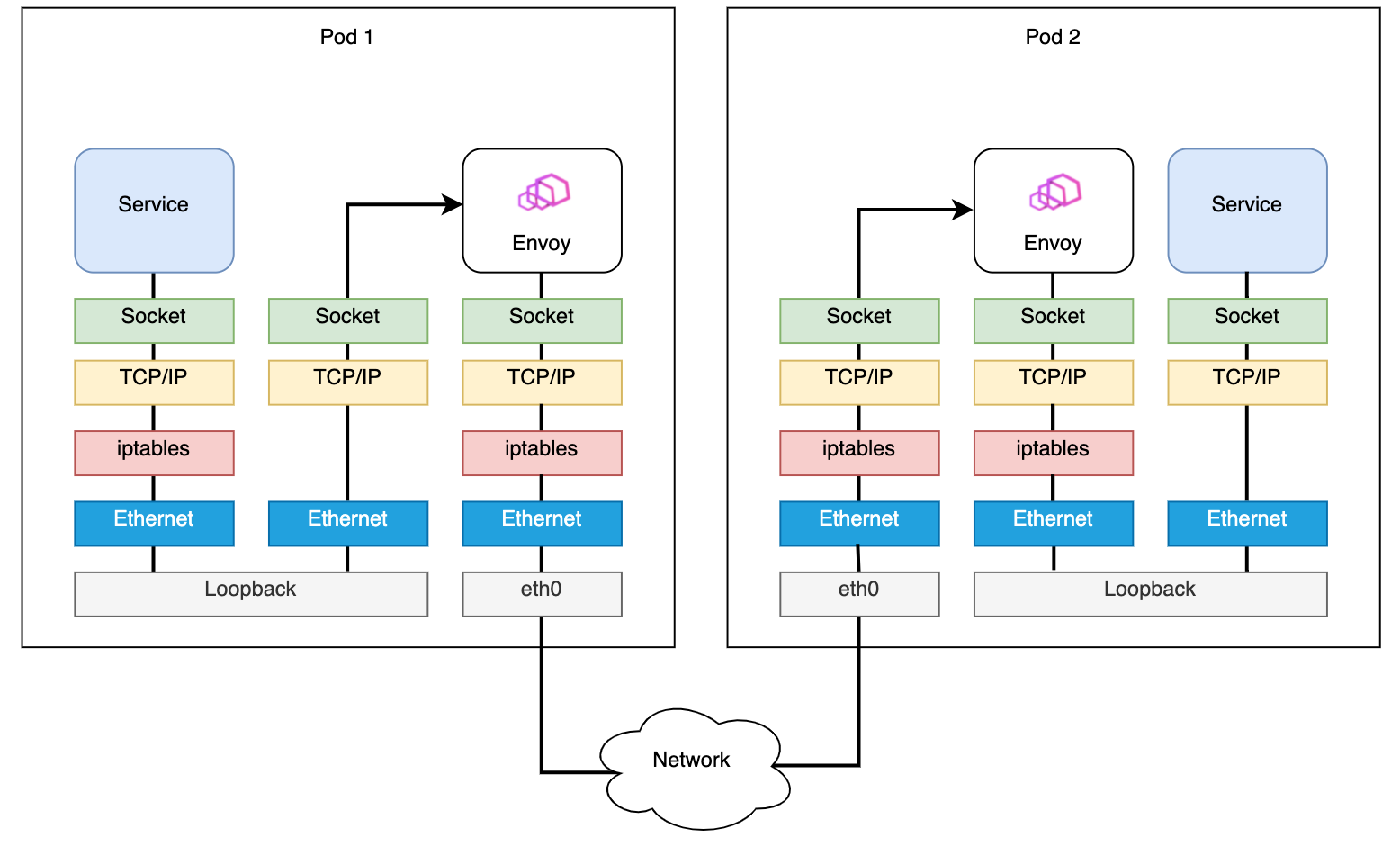
Antes de aplicar eBPF usando Merbridge, la ruta de datos entre pods es:
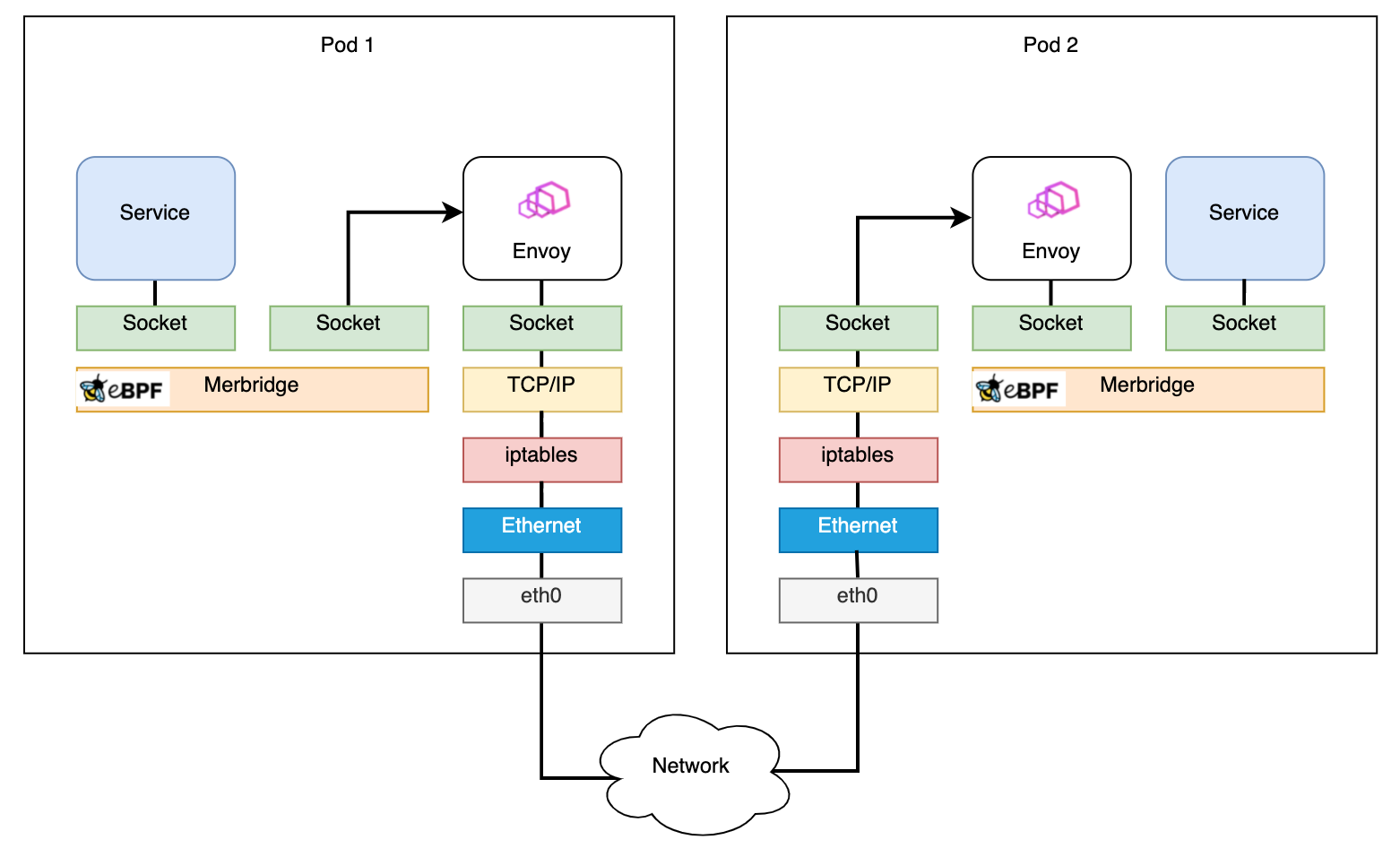
Después de aplicar Merbridge, el tráfico de salida se saltará muchos pasos de filtrado para mejorar el rendimiento:
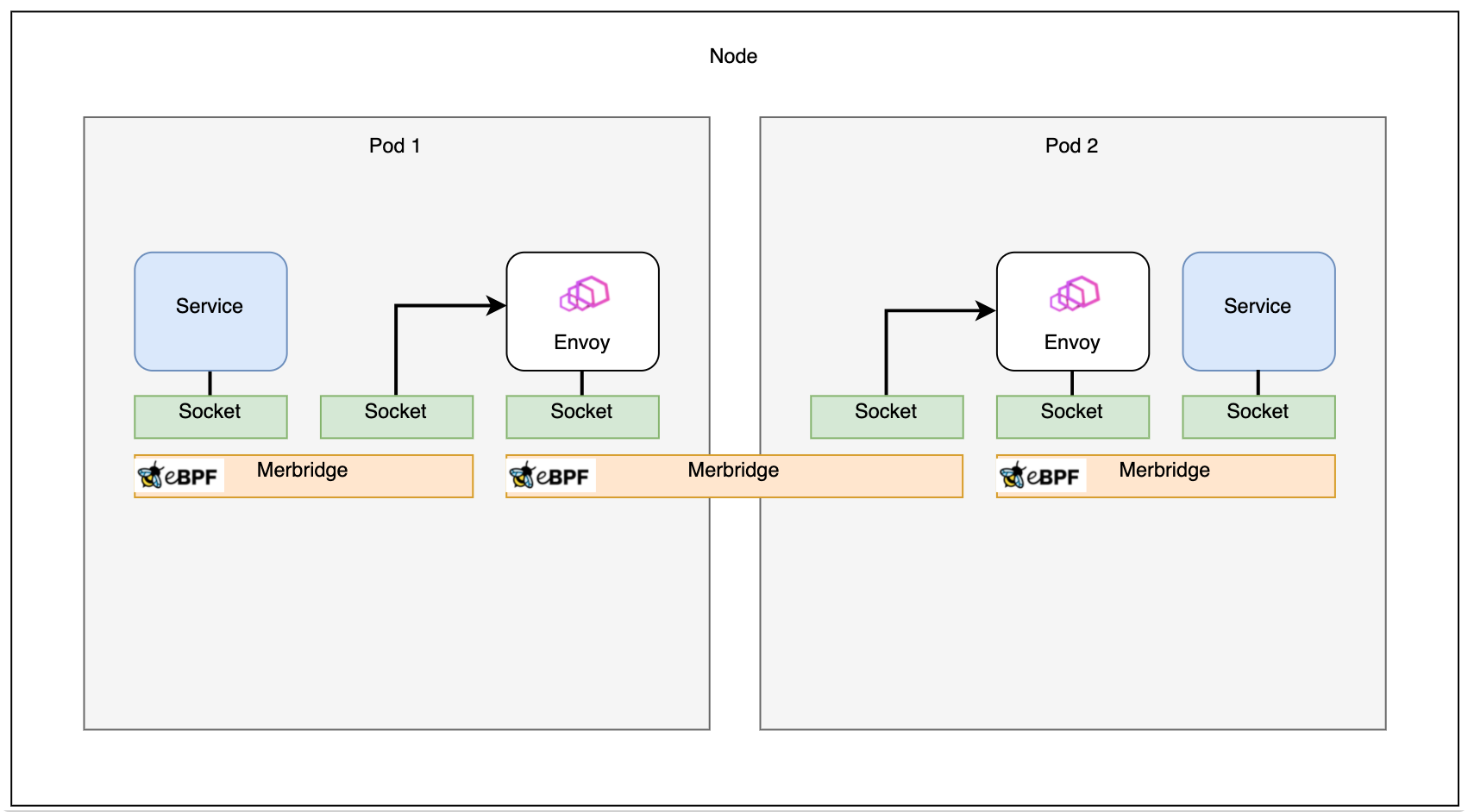
Si dos pods están en la misma máquina, la conexión puede ser aún más rápida:
Resultados de rendimiento
Veamos el efecto en la latencia general usando eBPF en lugar de iptables (más bajo es mejor):
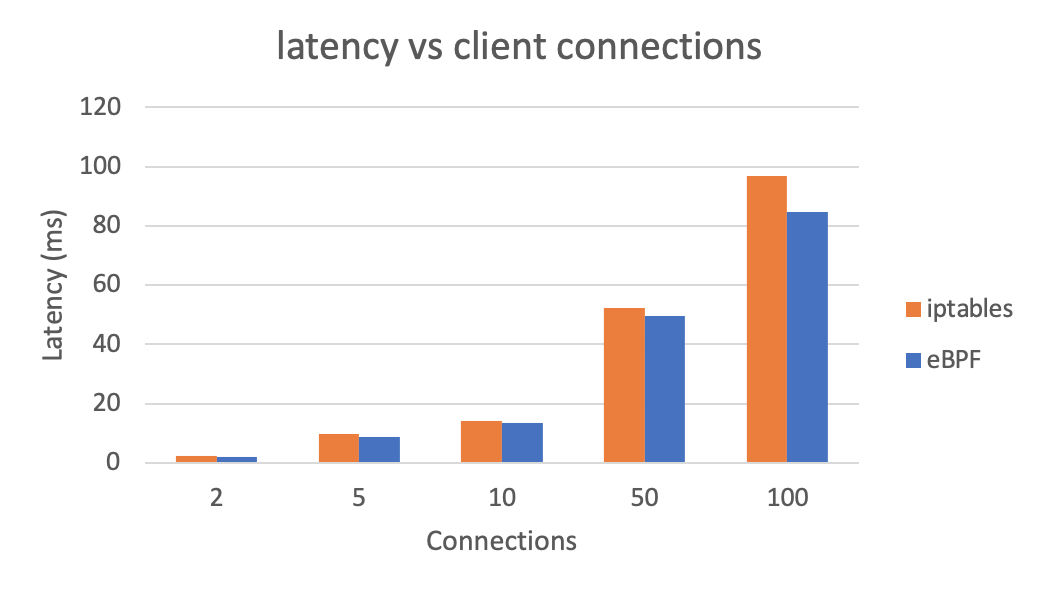
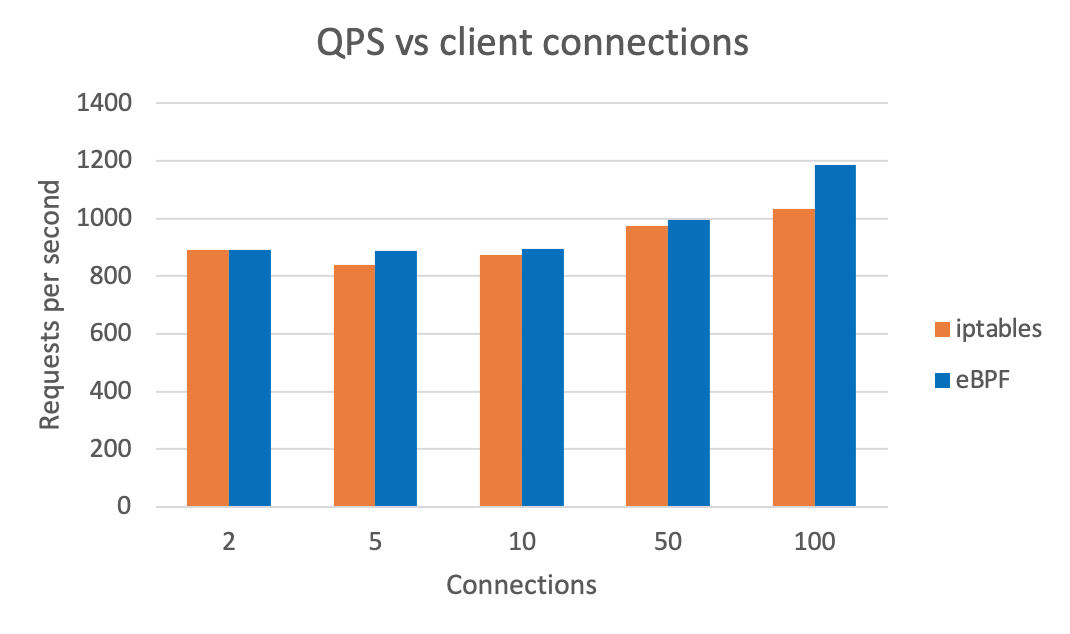
También podemos ver el QPS total tras usar eBPF (más alto es mejor). Los resultados se generan con wrk.
Resumen
En este post hemos presentado las ideas principales de Merbridge. Reemplazando iptables con eBPF, el proceso de transporte de datos puede acelerarse en un escenario de mesh. Al mismo tiempo, Istio no se modifica en absoluto. Esto significa que si ya no quieres usar eBPF, basta con borrar el DaemonSet y el datapath volverá al enrutamiento tradicional basado en iptables sin problemas.
Merbridge es un proyecto open source completamente independiente. Aún está en una etapa temprana, y esperamos que más usuarios y desarrolladores se involucren. Agradeceríamos mucho que pruebes esta nueva tecnología para acelerar tu mesh y nos compartas feedback.
Ver también
- Merbridge en GitHub
- Using eBPF instead of iptables to optimize the performance of service grid data plane por Liu Xu, Tencent
- Sidecar injection and transparent traffic hijacking process in Istio explained in detail por Jimmy Song, Tetrate
- Accelerate the Istio data plane with eBPF por Yizhou Xu, Intel
- Filtro Original Destination de Envoy


